

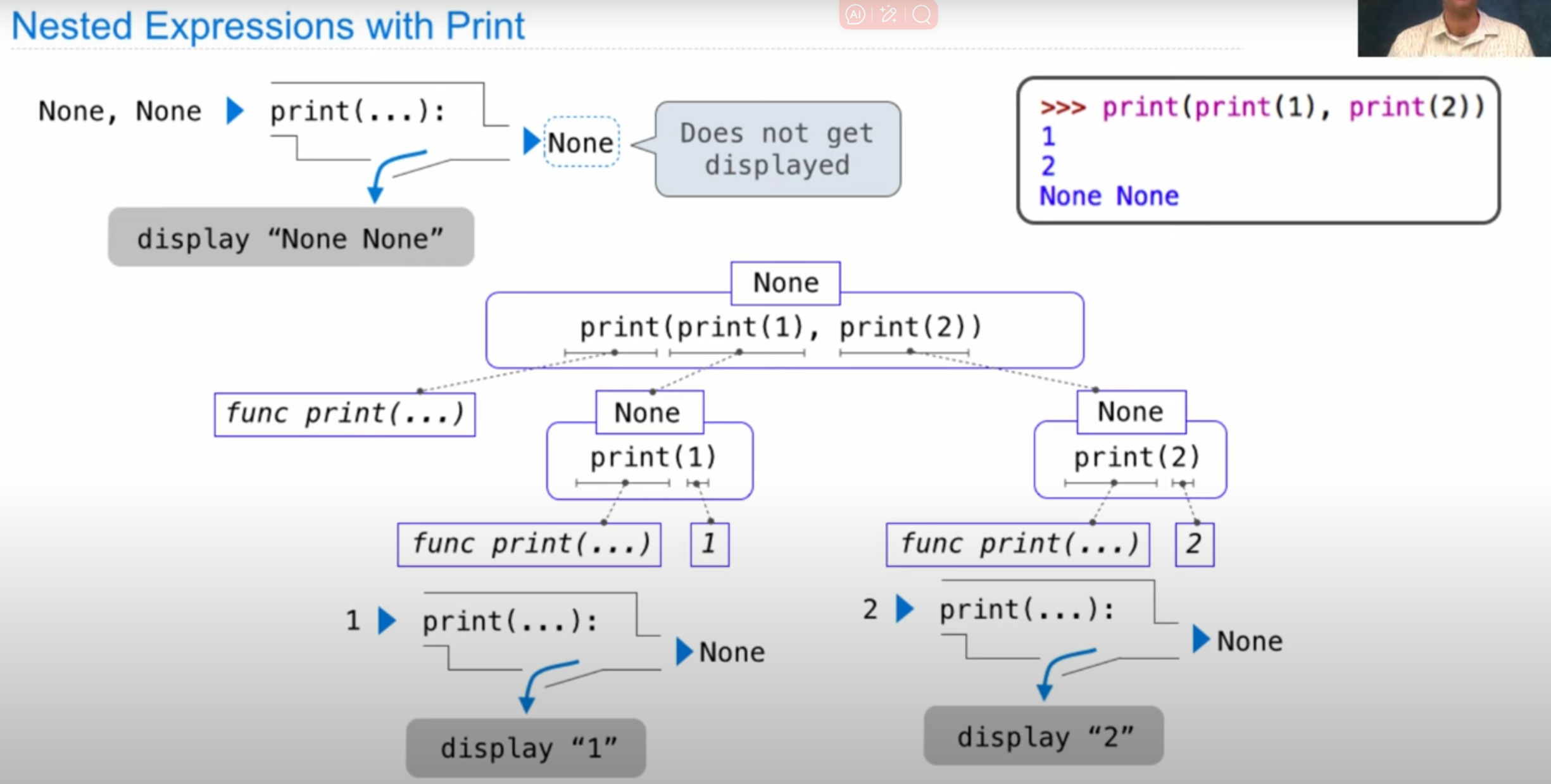
print(print(1),print(2)) |
Casual Literary Notes
Note: When we say condition is a predicate function, we mean that it is a function that will return True or False.
Python Tutor code visualizer: Visualize code in Python, JavaScript, C, C++, and Java
Questions
Q5: Count Stair Ways
Imagine that you want to go up a flight of stairs that has n steps, where n is a positive integer. You can take either one or two steps each time you move. In how many ways can you go up the entire flight of stairs?
You’ll write a function count_stair_ways to answer this question. Before you write any code, consider:
- How many ways are there to go up a flight of stairs with
n = 1step? What aboutn = 2steps? Try writing or drawing out some other examples and see if you notice any patterns.
Solution: When there is only one step, there is only one way to go up. When there are two steps, we can go up in two ways: take a single 2-step, or take two 1-steps.
- What is the base case for this question? What is the smallest input?
Solution: We actually have two base cases! Our first base case is when there is one step left. n = 1 is the smallest input because 1 is the smallest positive integer.
Our second base case is when there are two steps left. The primary solution (found below) cannot solve count_stair_ways(2) recursively because count_stair_ways(0) is undefined.
(virfib has two base cases for a similar reason: virfib(1) cannot be solved recursively because virfib(-1) is undefined.)
Alternate solution: Our first base case is when there are no steps left. This means we reached the top of the stairs with our last action.
Our second base case is when we have overstepped. This means our last action was invalid; in other words, we took two steps when only one step remained.
Solution: count_stair_ways(n - 1) is the number of ways to go up n - 1 stairs. Equivalently, count_stair_ways(n - 1) is the number of ways to go up n stairs if our first action is taking one step.
count_stair_ways(n - 2) is the number of ways to go up n - 2 stairs. Equivalently, count_stair_ways(n - 2) is the number of ways to go up n stairs if our first action is taking two steps.
Now, fill in the code for count_stair_ways:
Your Answer
Solution
def count_stair_ways(n): |
Here’s an alternate solution that corresponds to the alternate base cases:
def count_stair_ways_alt(n): |
You can use [Recursion Visualizer](https://www.recursionvisualizer.com/?function_definition=def count_stair_ways(n)%3A if n %3D%3D 1%3A return 1 elif n %3D%3D 2%3A return 2 return count_stair_ways(n-1) %2B count_stair_ways(n-2)&function_call=count_stair_ways(4)) to step through the call structure of count_stair_ways(4) for the primary solution.
You’re done! Excellent work this week. Please be sure to fill out your TA’s attendance form to get credit for this discussion!
Q6: Subsequences
A subsequence of a sequence S is a subset of elements from S, in the same order they appear in S. Consider the list [1, 2, 3]. Here are a few of its subsequences [], [1, 3], [2], and [1, 2, 3].
Write a function that takes in a list and returns all possible subsequences of that list. The subsequences should be returned as a list of lists, where each nested list is a subsequence of the original input.
In order to accomplish this, you might first want to write a function insert_into_all that takes an item and a list of lists, adds the item to the beginning of each nested list, and returns the resulting list.
Your Answer
Solution
def insert_into_all(item, nested_list): |
Discussion 6: Generators| CS 61A Fall 2025
Q3: Partitions
Tree-recursive generator functions have a similar structure to regular tree-recursive functions. They are useful for iterating over all possibilities. Instead of building a list of results and returning it, just yield each result.
You’ll need to identify a recursive decomposition: how to express the answer in terms of recursive calls that are simpler. Ask yourself what will be yielded by a recursive call, then how to use those results.
Definition. For positive integers n and m, a partition of n using parts up to size m is an addition expression of positive integers up to m in non-decreasing order that sums to n.
Implement partition_gen, a generator functon that takes positive n and m. It yields the partitions of n using parts up to size m as strings.
Reminder: For the partitions function we studied in lecture (video), the recursive decomposition was to enumerate all ways of partitioning n using at least one m and then to enumerate all ways with no m (only m-1 and lower).
Hint: For the base case, yield a partition with just one element, n. Make sure you yield a string.
Hint: The first recursive case uses at least one m, and so you will need to yield a string that starts with p but also includes m. The second recursive case only uses parts up to size m-1. (You can implement the second case in one line using yield from.)
def partition_gen(n, m): |
Discussion Time. Work together to explain why this implementation of partition_gen does not include base cases for n < 0, n == 0, or m == 0 even though the original implementation of partitions from lecture (video) had all three.
Q4: Squares
Implement the generator function squares, which takes positive integers total and k. It yields all lists of perfect squares greater or equal to k*k that sum to total. Each list is in non-increasing order (large to small).
def squares(total, k): |
Lab 5: Mutability, Iterators | CS 61A Fall 2025
# Tree Data Abstraction |
Q7: Sprout Leaves
Define a function sprout_leaves that takes in a tree t and a list of leaf labels leaves. It returns a new tree that is identical to t, but in which each old leaf node has new branches, one for each leaf label in leaves.
For example, say we have the tree t = tree(1, [tree(2), tree(3, [tree(4)])]):
1 |
1 |
def sprout_leaves(t, leaves): |
Q8: Pruning Leaves
Implement prune_leaves, which takes a tree t and a tuple of values vals. It returns a version of t with all its leaves whose labels are in vals removed. Do not remove non-leaf nodes and do not remove leaves that do not match any of the items in vals. Return None if pruning the tree results in there being no nodes left in the tree.
def prune_leaves(t, vals): |
def prune_leaves(t, vals): |
解法一对于每一个子树 b,调用了两次 prune_leaves!所以第一种写法虽然看着“帅气简洁”,实则是个**“性能杀手”**。
虽然第二种写法赢麻了,但它的 Base Case(基本情况) 写法稍微有一点点“隐晦”(虽然逻辑是对的)。
最完美的融合怪写法是这样的:
def prune_leaves_perfect(t, vals): |
Q9: Path Sum
Define a function pathsum, which takes in a tree of numbers t and a number n. It returns True if there is a path from the root to a leaf such that the sum of the numbers along that path is n and False otherwise.
def pathsum(t, n): |
def pathsum(t, n): |
如果你真的很喜欢 any 的简洁,其实只需要改两个符号,它就能变成完美的写法!
把方括号 [] 去掉(或者换成圆括号),变成 生成器表达式 (Generator Expression):
# 这样写就是满分!return any(pathsum(b, n - label(t)) for b in branches(t))
def pathsum(t, n): |
Q10: Perfectly Balanced
Implement sum_tree, which returns the sum of all the labels in tree t.
def sum_tree(t): |
def sum_tree(t): |
Then, implement balanced, which returns whether every branch of t has the same total sum and that the branches themselves are also balanced.
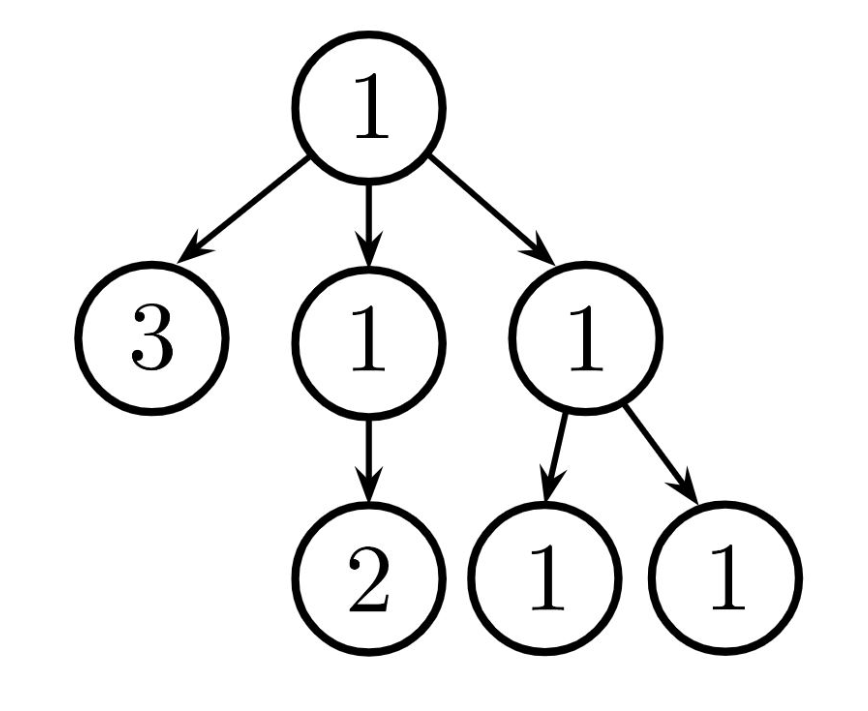
- For example, the tree above is balanced because each branch has the same total sum, and each branch is also itself balanced.
def balanced(t): |
def balanced(t): |
Homework 4: Sequences, Data Abstraction, Trees | CS 61A Fall 2025
Q5: Finding Berries!
The squirrels on campus need your help! There are a lot of trees on campus and the squirrels would like to know which ones contain berries. Define the function berry_finder, which takes in a tree and returns True if the tree contains a node with the value 'berry' and False otherwise.
def berry_finder(t): |
def berry_finder(t): |
Q6: Maximum Path Sum
Write a function that takes in a tree of positive numbers and returns the maximum sum of the labels along any root-to-leaf path in the tree. A root-to-leaf path is a sequence of nodes starting at the root and ending at some leaf of the tree.
def max_path_sum(t): |
Discussion 5: Trees | CS 61A Fall 2025

Q2: Has Path
Implement has_path, which takes a tree t and a list p. It returns whether there is a path from the root of t with labels p. For example, t1 has a path from its root with labels [3, 5, 6] but not [3, 4, 6] or [5, 6].
Important: Before trying to implement this function, discuss these questions from lecture about the recursive call of a tree processing function:
- What small initial choice can I make (such as which branch to explore)?
- What recursive call should I make for each option?
- How can I combine the results of those recursive calls?
- What type of values do they return?
- What do those return values mean?
def has_path(t, p): |
def has_path(t, p): |
Q3: Find Path
Implement find_path, which takes a tree t with unique labels and a value x. It returns a list containing the labels of the nodes along a path from the root of t to a node labeled x.
If x is not a label in t, return None. Assume that the labels of t are unique.
def find_path(t, x): |
Q4: Only Paths
Implement only_paths, which takes a Tree of numbers t and a number n. It returns a new tree with only the nodes of t that are on a path from the root to a leaf with labels that sum to n, or None if no path sums to n.
Here is an illustration of the doctest examples involving t.

这道 only_paths 是一道非常经典的 “修剪树木” (Tree Pruning) 问题。
这道题最难的地方不在于怎么往下走(递归),而在于怎么回头。如果一条路走不通,你不仅要告诉下面“不行”,还得让上面知道“我这儿变成死胡同了,把我也剪掉吧”!✂️
错误分析:
if is_leaf(t) and label(t) == n: |
死树桩问题” (Dead Stump Problem):
场景模拟: 假设你是一个节点 3,你的目标是 10。你不是叶子。 你派手下去找 7。结果手下全都失败了,返回了 None。 你的 new_branches 变成了空列表 []。
你的操作:你非常开心地返回了一个 tree(3, [])。
后果: 虽然你的孩子都死光了,但你自己还活着!你变成了一个没有任何子节点的叶子节点,且你的值 3 并不等于目标 10。 上一层看到你返回了一个 tree 对象(而不是 None),以为你这条路通了,把你接到了树上。 结果就是:树里多了一堆**“假叶子”**(本来不该存在的死胡同)。
Solution:
def only_paths(t, n): |
def only_paths(t, n): |
def only_paths(t, n): |
📝 题目描述
实现函数
long_paths(t, n):
- 输入:一棵树
t和一个整数n。- 功能:修剪这棵树,只保留那些属于“长度至少为 n”的路径上的节点。(路径长度定义为该路径上节点的数量,包含根节点和叶子节点)。
- 返回:修剪后的新树。如果整棵树里没有一条路径能达到长度
n,则返回None。
好哒!既然刚才那道“死树桩”问题你已经悟了,那本天才少女要给你上一道进阶变体!😈
这道题的逻辑骨架和 only_paths 非常像,但它考察的角度从“求和 (Sum)”变成了“深度 (Depth)”。这在路径规划算法里可是非常核心的概念哦!
我们叫它:long_paths (长路漫漫) 🛣️
📝 题目描述
实现函数 long_paths(t, n):
- 输入:一棵树
t和一个整数n。 - 功能:修剪这棵树,只保留那些属于“长度至少为 n”的路径上的节点。(路径长度定义为该路径上节点的数量,包含根节点和叶子节点)。
- 返回:修剪后的新树。如果整棵树里没有一条路径能达到长度
n,则返回None。
🎨 可视化测试用例
假设我们有这样一棵树 t:
1 |
- 路径
1 -> 2长度为 2。 - 路径
1 -> 3 -> 5长度为 3。 - 路径
1 -> 3 -> 4 -> 6长度为 4。
🧪 测试用例 1: n = 3 (保留长度 >= 3 的路径)
1 -> 2(长度2) 太短了,剪掉! ✂️1 -> 3 -> 5(长度3) 保留! ✅1 -> 3 -> 4 -> 6(长度4) 保留! ✅
结果树:
1 |
🧪 测试用例 2: n = 4 (保留长度 >= 4 的路径)
1 -> 3 -> 5(长度3) 这次也太短了,剪掉! ✂️- 只剩下最长的那条。
结果树:
1 |
🧪 测试用例 3: n = 10
- 没有任何路径够长。
- 返回:
None
💻 代码填空挑战
请把下面的代码补全(注意:一定要避免死树桩问题!):
def long_paths(t, n): |
🧠 两个关键提示
- 关于
n的递归: 在only_paths里,我们往下传的是n - label(t)(做减法)。 在这里,每下一层,路径长度的要求就少了一层节点,所以往下传应该是n - 1。 - 关于“死树桩”的判定: 这题比
only_paths多了一个小陷阱。 在only_paths里,如果孩子都死光了,那我就必死(除非我是 Base Case)。 但在这里,如果n <= 1,说明**“只要有我这个节点,路径长度就已经达标了”**。此时即使我没有孩子(filtered_branches为空),我也应该活下来! 所以第 4 步的if条件要小心哦!
Discussion 4: Tree Recursion | CS 61A Fall 2025
Q1: Insect Combinatorics
An insect is inside an m by n grid. The insect starts at the bottom-left corner (1, 1) and wants to end up at the top-right corner (m, n). The insect can only move up or to the right. Write a function paths that takes the height and width of a grid and returns the number of paths the insect can take from the start to the end. (There is a closed-form solution to this problem, but try to answer it with recursion.)
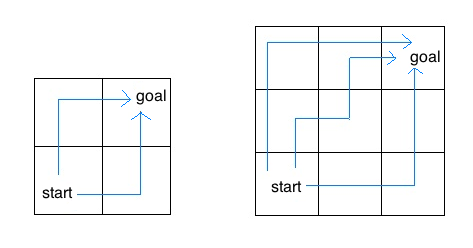
In the 2 by 2 grid, the insect has two paths from the start to the end. In the 3 by 3 grid, the insect has six paths (only three are shown above).
Hint: What happens if the insect hits the upper or rightmost edge of the grid?
def paths(m, n): |
# The recursive case is that there are paths from the square to the right through an (m, n-1) grid and paths from the square above through an (m-1, n) grid. |
def paths(m, n): |
Q2: Max Product
Implement max_product, which takes a list of numbers and returns the maximum product that can be formed by multiplying together non-consecutive elements of the list. Assume that all numbers in the input list are greater than or equal to 1.
Hint: First try multiplying the first element by the max_product of everything after the first two elements (skipping the second element because it is consecutive with the first), then try skipping the first element and finding the max_product of the rest. To find which of these options is better, use max.
Your Answer
def max_product(s): |
Q3: Sum Fun
Implement sums(n, m), which takes a total n and maximum m. It returns a list of all lists:
- that sum to
n, - that contain only positive numbers up to
m, and - in which no two adjacent numbers are the same.
Two lists with the same numbers in a different order should both be returned.
Here’s a recursive approach that matches the template below: build up the result list by building all lists that sum to n and start with k, for each k from 1 to m. For example, the result of sums(5, 3) is made up of three lists:
[[1, 3, 1]]starts with 1,[[2, 1, 2], [2, 3]]start with 2, and[[3, 2]]starts with 3.
Hint: Use [k] + s for a number k and list s to build a list that starts with k and then has all the elements of s.
**Hint: First Blank: **k is the first number in a list that sums to n, and rest is the rest of that list, so build a list that sums to n.
**Hint: Second Blank: **Call sums to build all of the lists that sum to n-k so that they can be used to construct lists that sum to n by putting a k on the front.
**Hint: Third Blank: **Here is where you ensure that “no two adjacent numbers are the same.” Since k will be the first number in the list you’re building, it must not be equal to the first element of rest (which will be the second number in the list you’re building).
def sums(n, m): |
Q4: A Perfect Question
This question was Fall 2023 Midterm 2 Question 4(a). The original exam version had an extra blank (where total < k * k appears below), but also included some guidance via multiple choice options and hints.
Definition. A perfect square is k*k for some integer k.
Implement fit, which takes positive integers total and n. It returns True or False indicating whether there are n positive perfect squares that sum to total. The perfect squares need not be unique.
def fit(total, n): |
def fit(total, n): |
Computer Aided Typing Software (Cats) | CS 61A Fall 2025
Problem 6 (3 pts)
Implement furry_fixes, a diff function that could be passed into the diff_function parameter in autocorrect. This function takes in two strings and returns the minimum number of characters that must be changed in the typed word in order to transform it into the source word. If the strings are not of equal length, the difference in lengths is added to the total change count.
Here are some examples:
big_limit = 10 |
Important: You may not use
while,for, or list comprehensions in your implementation. Use recursion.
If the number of characters that must change is greater than limit, then furry_fixes should return any number larger than limit and should minimize the amount of computation needed to do so.
Why is there a limit? From Problem 5, we know that
autocorrectwill reject anysourceword whose difference with thetypedword is greater thanlimit. It doesn’t matter if the difference is greater thanlimitby 1 or by 100; autocorrect will reject it just the same. Therefore, as soon as we know the difference is abovelimit, it makes sense to stop making recursive calls, saving time, even if the returned difference won’t be exactly correct.These two calls to
furry_fixesshould take about the same amount of time to evaluate:
>>> furry_fixes("roses", "arose", limit) > limit
True
>>> furry_fixes("rosesabcdefghijklm", "arosenopqrstuvwxyz", limit) > limit
True
To ensure that you are correctly saving time by stopping the recursion after limit is reached, there is an autograder test that measures the performance of your solution based on the number of function calls that it makes. If you fail this test, consider adding a base case related to the limit.
Hint: you will need more than one base case to solve this problem.
def furry_fixes(typed: str, source: str, limit: int) -> int: |
Problem 7 (3 pts)
Implement minimum_mewtations, a more advanced diff function that can be used in autocorrect, which returns the minimum number of edit operations needed to transform the typed word into the source word.
There are three kinds of edit operations, with some examples:
- Add a letter to
typed.- Adding
"k"to"itten"gives us"kitten".
- Adding
- Remove a letter from
typed.- Removing
"s"from"scat"gives us"cat".
- Removing
- Substitute a letter in
typedfor another.- Substituting
"z"with"j"in"zaguar"gives us"jaguar".
- Substituting
Each edit operation increases the difference between two words by 1.
big_limit = 10 |
We have provided a template of an implementation in cats.py. You may modify the template however you want or delete it entirely.
Hint: One of the recursive calls in
minimum_mewtationswill be similar tofurry_fixes. However, becauseminimum_mewtationsconsiders three specific types of edits (add, remove, substitute), there will need to be additional recursive calls to handle each of these cases.
If the number of edits required is greater than limit, then minimum_mewtations should return any number larger than limit (such as limit + 1) and should stop making recursive calls once the limit is reached to save time.
These two calls to
minimum_mewtationsshould take about the same amount of time to evaluate:
minimum_mewtations("ckiteus", "kittens", limit) > limit
True
minimum_mewtations("ckiteusabcdefghijklm", "kittensnopqrstuvwxyz", limit) > limit
True
To ensure that your code stops making recursive calls after the limit is reached, there is an autograder test that measures the performance of your solution based on the number of function calls that it makes.
Important: You should not use any helper functions in your implementation of
minimum_mewtations. Otherwise the autograder test might fail.Important: Remember to remove the following line of code when you are ready to test your implementation:
def minimum_mewtations(typed: str, source: str, limit: int) -> int: |
Dynamic Programming iterable version:
def editDistance(typed, source): |
(Optional) Problem EC (0 pt)
Note: This problem is optional and will not worth any points. It is meant to be a extra challenge for those who are interested in improving the efficiency of their code. Only attempt this problem if you have completed all other problems in the project.
During Office Hours and Project Parties, the staff will prioritize helping students with required questions. We will not be offering help with this question unless the queue is empty. In this problem, you will implement memoization decorators that will increase the efficiency of our our program by “remembering” the results of particularly intensive operations.
Make sure you’re familiar with the decorators and memoization. If you would like a refresher, open the dropdown boxes below for more information.
Decorators
A Python decorator allows you to modify a pre-existing function without changing the function’s structure.
Specifically, a decorator function is a higher-order function that…
- Takes the original function as an input
- Returns a new function with modified functionality
- This new function must contain the same arguments as the original function
An example of a decorator that executes a one-input function twice is shown below:
def do_twice(original_function): |
We can apply this function in multiple contexts:
# Printing a value twice |
Additionally, note that we could also directly call the decorator function instead of using the @ notation (i.e. print_value = do_twice(print_value)). However, it’s typically useful to place decorators directly above the function that we are modifying since they better describe how these functions are being changed in our code.
Memoization
Notice that the diff functions we wrote in the previous questions are very inefficient: you will likely find that the computer will make the same recursive call multiple times. For a function with multiple arguments and three recursive calls, this can be harder to see. It can be easier to first see this with a function like fib that is defined in lecture.
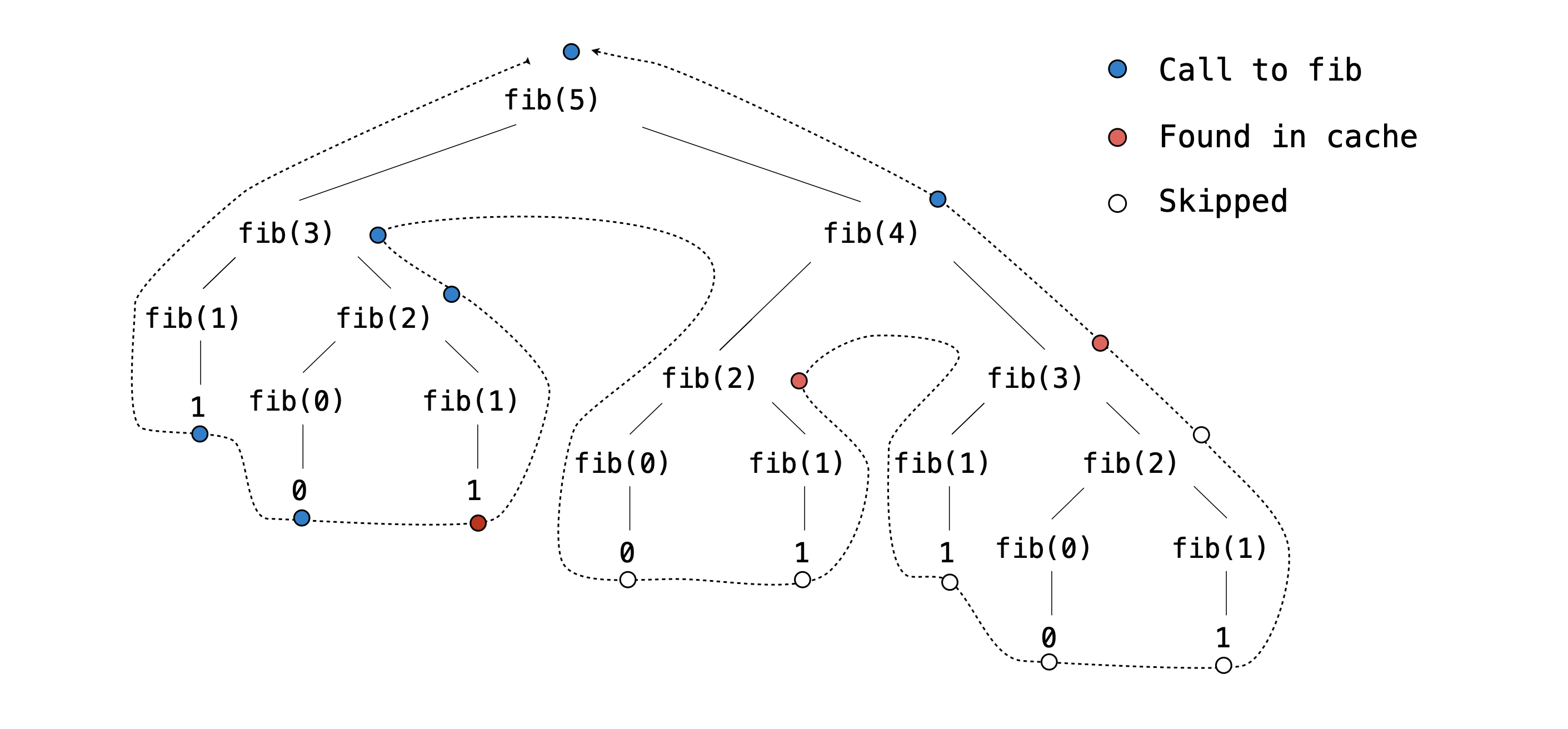
Noticed how many redundant recursive calls there are in the above tree diagram. Our goal is to have our program store past results of evaluated recursive calls so that we can reuse them if the same recursive call comes up in the future. For example, the first branch of fib(5) calls fib(3), which has not yet been evaluated. So we must go through all of its subsequent recursive calls to find its return value. However when we encounter the call to fib(3) that is a branch of fib(4), we have already found its return value before! So if we have a way to store and retrieve that information in something called a cache, we can avoid needless computation. We no longer need to make any subsequent recursive calls to its branches fib(1) and fib(2). This is the concept of memoization: store the results of expensive computations in a cache, and retrieve information from the cache in the case we execute a repeated action.
We will be working with two memoization decorators. memo is a general all-purpose decorator that memoizes the function it annotates. If memo encounters an input it has not seen, it will store the calculated result into its cache. If memo receives an input it has already seen, it will take the stored value in the cache and returns it directly without doing any extra computation. We have provided you with the full implementation of memo.
Your task is to implement memo_diff. memo_diff is a higher-order function that takes in a diff_function and returns another diff function called memoized that, like all diff functions, takes in typed, source, and limit. memoized should do the following:
- When
memoizedsees a (typed,source) pair for the first time, it should calculate the difference usingdiff_functionand cache that value along with thelimitused as a (value,limit) tuple pair. - If
memoizedencounters the (typed,source) pair again, it should return the memoizedvalueif the providedlimitis less than or equal to the cached limit. Otherwise, the difference should be recalculated, recached, and returned.
Important: When implementing this function, make sure you store pairs of values in the cache with a tuple, not a list. In dictionaries, keys must be immutable (that’s why using a tuple is fine, but using a list is not). If you’re curious about why
memo_diffis different thanmemoand is implemented in this way, reference the dropdown below:
More information
How do memo and memo_diff differ? Although memo stores only the result of a function call, memo_diff takes into account an additional constraint, limit, that affects whether the cached result can be used or not. When the memo_diff function is called with a (typed, source) pair, it doesn’t just check if the pair has been seen before; it also checks if the limit is less than or equal to the cached limit. This is an additional check that memo does not perform.
Why is limit handled this way? We already know that the limit represents the maximum difference that a diff function cares about—that is, differences above the limit might as well be the same. So diff functions will provide an accurate difference value when it is below the limit and an inaccurate one when it is above the limit. Therefore, we can trust a cached difference value if it was calculated with a higher limit, but we can’t trust ones calculated with a lower limit.
For example, the result of the first call below would allow us to predict the result of the second call. The higher limit provides us with more information. However, the second call would not allow us to predict the first one.
minimum_mewtations("hello", "hasldfasdfsffsfasdf", 100) |
Once you’ve implemented memo_diff, finish by:
- Decorating
autocorrectwithmemo. - Decorating
minimum_mewtationswithmemo_diff.
Running autocorrect and minimum_mewtations should now be much faster!
Note: If you are failing the autograder tests involving
call_count, it is likely that yourminimum_mewtationsimplementation (from Q7) is not having the tightest base cases possible and still needs some optimization. The tests from Q7 are not meant to be strict, so even if you passed the Q7 tests, your base cases might still not be the tightest. Make sure you are not making unnecessary recursive calls. We are being strict about this here because having the tightest base cases is crucial for the efficiency of your code.Important: Try it yourself first! Only consult the following common mistakes section if you have been stuck on one test case for a while. Otherwise, you might not learn as much from the project.
Common Mistakes
- Consider the case
minimum_mewtations(typed = "maooo", source = "mao", limit = 0): since no transformations are allowed and the two words are not the same, how quick can your function figure out that the result is impossible? - Consider the case
minimum_mewtations(typed = "habc", source = "hmao", limit = some_limit_greater_than_zero): Given that both strings start with the same characterh, what is the most effective approach in this situation? Should the function even attempt to “add” (resulting inhabcandmao) or “remove” (resulting inabcandhmao)? Does your implementation take advantage of this optimization?
Note: The autograder takes a bit of time to run, but it should not be longer than 10 seconds.
def memo(f): |
def minimum_mewtations(typed: str, source: str, limit: int) -> int: |
